
Perceptual Audio Test Options
APx500 supports two popular perceptual audio tests used for speech quality evaluation: POLQA (Perceptual Objective Listening Quality Assessment) and PESQ (Perceptual Evaluation of Speech Quality). Both deliver Mean Opinion Score (MOS) results directly in APx projects.
PESQ is a widely used, enhanced perceptual measurement for voice quality in telecommunications. It is licensed from OPTICOM GmbH and forms the basis of ITU-T Recommendation P.862. PESQ is specifically designed for testing voice quality on low bandwidth devices, like mobile phones and smartphones. MOS results from PESQ can achieve a very high correlation with results obtainable using human subjects.
POLQA is licensed from OPTICOM as a successor to PESQ, and specifically targets changes in the communications landscape with support for HD Voice, 3G, 4G/LTE and VoIP technologies. Like PESQ, POLQA delivers results with a very high correlation to tests with human subjects.
Beyond “Regular” Audio Testing
Many voice communications devices, notably mobile phones and VoIP networks, employ limited bandwidth and/or bitrate, and use codecs that significantly alter sound. Despite these accommodations, people can usually understand one another quite well over these systems; this is because the compromises made are selected to allow adequate speech perception despite measurable shortcomings in distortion, frequency response, and other traditional audio metrics.
PESQ and POLQA simulate the likely results of real human subjects with real speech samples, allowing designers of speech-delivery systems to ensure that real-world customers achieve high levels of product satisfaction.
PESQ/POLQA Methodology
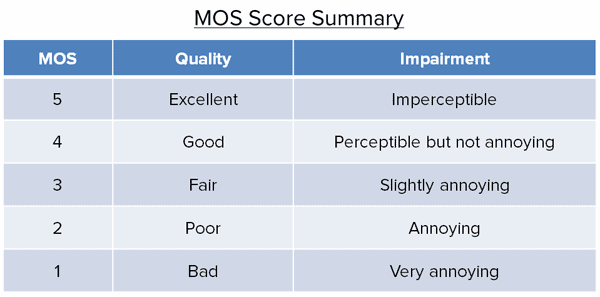
In traditional perceptual measurements, a group of people is assembled and asked to judge the sound quality of various audio clips, typically on a scale from 1 to 5. When all the individual scores are tallied, the result is called the Mean Opinion Score (MOS).
Tests with real human subjects are expensive and time consuming, but these limitations can be overcome by using tools that incorporate algorithms based upon psychoacoustic modeling, such as PESQ or POLQA. When used properly, these models closely match results from human groups. This automation allows for rapid iterations in development as well as efficient production line verification. Measurements obtained are classified as objective because they are unaffected by human temperament or test conditions, and the results are completely repeatable.
PESQ and POLQA are based upon ITU-T P.862 and P.863 respectively, and licensed by OPTICOM GmbH.
How Perceptual Audio Tests Work
Both reference and degraded signals are individually level aligned and filtered with the transfer characteristics of a receiving device (handset). The two signals are time aligned in order to compensate for small time shifts that can occur in voice networks due to delay, jitter and coding. The model transforms the two aligned and filtered signals from the time-amplitude domain into a frequency-loudness domain (auditory transform), accounting for the distortions that are perceptible by a human listener.
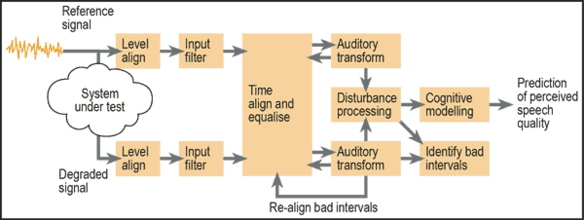
PESQ Block Diagram – Perceptual audio test block diagram (courtesy of OPTICOM GmbH)
The two signal representations are subtracted and an estimate of the audible differences is derived. The audible differences are accumulated over time, weighted differently depending on whether a distortion was added to the signal or if parts of the signal were missing after the transmission (e.g. drop-outs).
Finally after the analysis a single Mean Opinion Score (MOS) is generated. The MOS is commonly used to describe the voice quality on a scale from 1 (bad quality) to 5 (excellent quality).
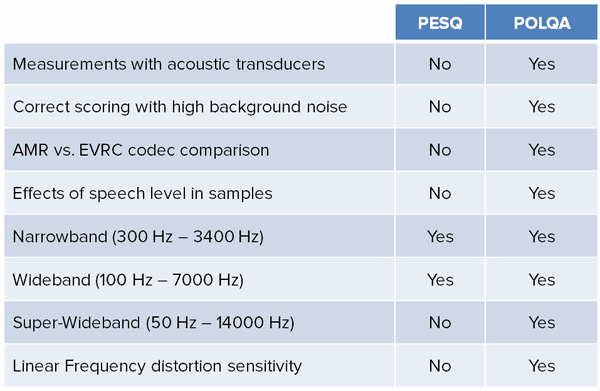
PESQ vs. POLQA
PESQ and POLQA are similar in goal, but differ in several key applications. PESQ is an older, but very widely used tool for evaluating speech quality on communications networks with restricted bandwidth, while POLQA is newer and handles variations such as wide-band audio, acoustic transducers, DSP and level variations. Many products specify one or the other as part of a testing and approval regimen.
PESQ and POLQA differences are summarized in the table below.
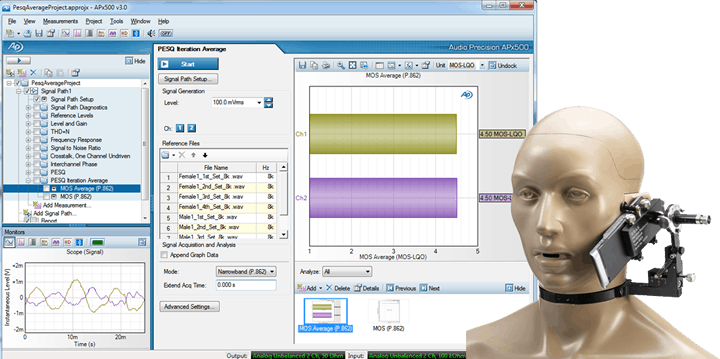
Perceptual Audio Testing in APx500
AP offers PESQ and POLQA as separate software options that operate in similar fashion, offering standard MOS results for a single speech sample and averaged measurements for accumulated samples.
The PESQ/POLQA measurement returns overall perceptual quality in MOS or PESQ units after playing each voice sample, along with a quality vs. time display to help pinpoint specific problems such as clipped words or dropouts. Additional results show average delay, delay vs. time, and the reference and the acquired waveforms.
The PESQ/POLQA Average measurement allows you to run a collection of different voice samples and then display the resulting overall score.
Both measurements let you choose to analyze the entire signal, or to look at only the active speech or silence.
Fully integrated with APx projects
Audio Precision’s PESQ and POLQA software options appear in projects exactly like any other measurement, with the same ease of use that makes APx500 software fast, productive and intuitive. All standard and optional I/O modules may be used, including unbalanced/balanced analog, unbalanced/balanced/optical digital, serial digital, Bluetooth, HDMI, and PDM.
PESQ OPTION SPECIFICATIONS
- ITU-T P.862.x Perceptual Evaluation of Speech Quality with mapping to MOS scale
- Narrowband and Wideband operation
- Input
- 16 bit linear audio sampled at 8 kHz or 16 kHz
Input voice files 6 to 20 seconds in length
- 16 bit linear audio sampled at 8 kHz or 16 kHz
- Measurements
- MOS
- PESQ
- Instantaneous MOS vs time
- Average MOS (Active Speech and Silence)
- MOS per sample file
POLQA OPTION SPECIFICATIONS
- ITU-T P.863 Perceptual Evaluation of Speech Quality with mapping to MOS scale
- Narrowband, Wideband and Super Wideband operation
- Use with acoustical interfaces
- Enhanced accuracy
- Input
- 16 bit linear audio sampled at 8, 16 or 48 kHz
Input voice files 6 to 12 seconds in length
- 16 bit linear audio sampled at 8, 16 or 48 kHz
- Measurements
- MOS
POLQA
Instantaneous MOS vs time
Average MOS (Active Speech and Silence)
MOS per sample file
- MOS